1) Long story short
During one of my analytical projects, we’re trying to on unify and perform analysis on a string attribute with a variety kinds of foreign languages. Some really weird stuff happens with our generated output(csv). Strings embedded with “?”
“資訊部經?”~
“?ージャー”
were all over the place. Certain characters were pruned without clear patterns across all foreign languages with question mark “?”. The database should have been encoded in utf-8, supporting almost all languages. Wait, what does encoding mean? what is utf-8?
2) Encoding
UTF-8(8-bit Unicode Transformation Format) is a variant-length encoding that could represent nearly every language in the world into 1-4 bytes. The lower 7 bits are compatiple with ASCII, representing A-Za-z
Wikipedia
3) What happened?
A question mark “?” in utf-8 encoding was 0x3F, so we hexdump the binary of the datafile.
hexdump -n 1000000 -e '16/1 "%02X " " | "' -e '16/1 "%_p" "\n"' data.csv | grep "3F"
What we see for
“資訊部經?”~
the hexemical value was
“資訊部經\xe7\x3F\x86”
unfortuantely \xE7 \x86 alone was illegal in utf-8 so it won’t be displayed, so only 3F was converted into a “?”. From the phrase itself, we guess it’s actually :
“資訊部經理”
which means IT manager in Japanese Kanji and Traditional Chinese.
4) What’s really happening?
Based on the assumption that “理” was pruned into “?”, let’s see what’s “理” encoding in utf-8:
>>> print("理".encode("utf-8"))
b'\xe7\x90\x86'
Alright, so it means ‘\xe7\x90\x86’
represent it, looks familiar? Hexdumping the string we’re getting ‘\xe7\x3F\x86’
Pretty close and we’re seeing the \x90 became \x3F. But WHY?
5) Crazy Until
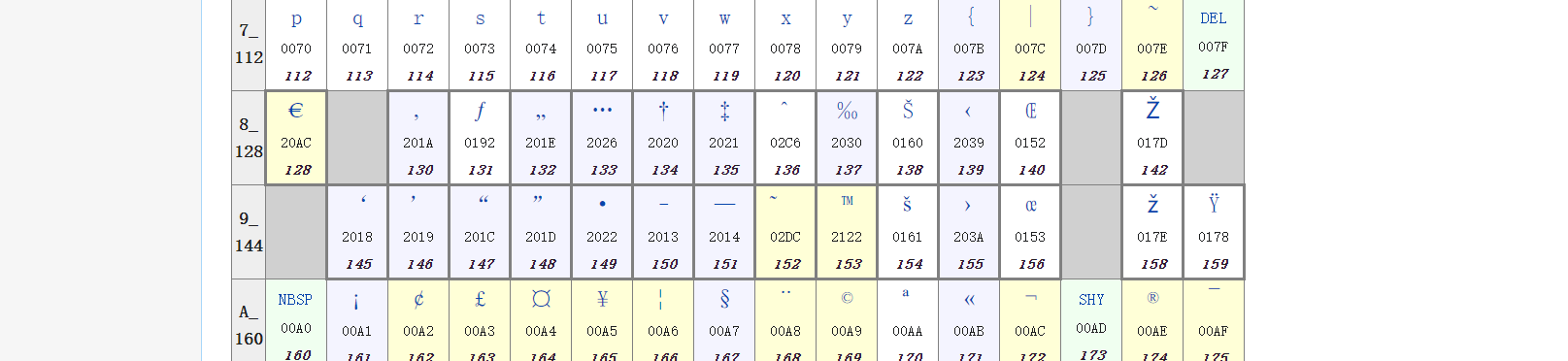
We found a few other byes pruned, including \x8F \x8D. I struggle for a few days looking for answers until it came up. The answer is Windows-1252. Windows-1252 was another quite popular encoding on Windows systems(Of course). In it, binary \x81 \x8D \x8F
\x90 \x9D were illegal/undefined, colored grey as show in wikipedia.
It could be that somehow some machine with that legacy encoding was in our analytics workflow and messes up all our data. To verify that assumption. I tried to reproduce with python as follows
str = "理"
dataInDB = str.encode("utf-8")
dataQuery = dataInDB.decode("Windows-1252","replace")
dataExported = dataQuery.encode("Windows-1252","replace")
>>> print(dataInDB.hex())
e79086
>>> print(dataExported)
b'\xe7?\x86'
Looks like this is it! A workstation with windows-1252 has messed up.
6) Lesson Learned
As Data Analytics or Engineers, stay sharp for those minor details, learn those boring data structures.